
Federated Learning
⚡ Definición Rápida
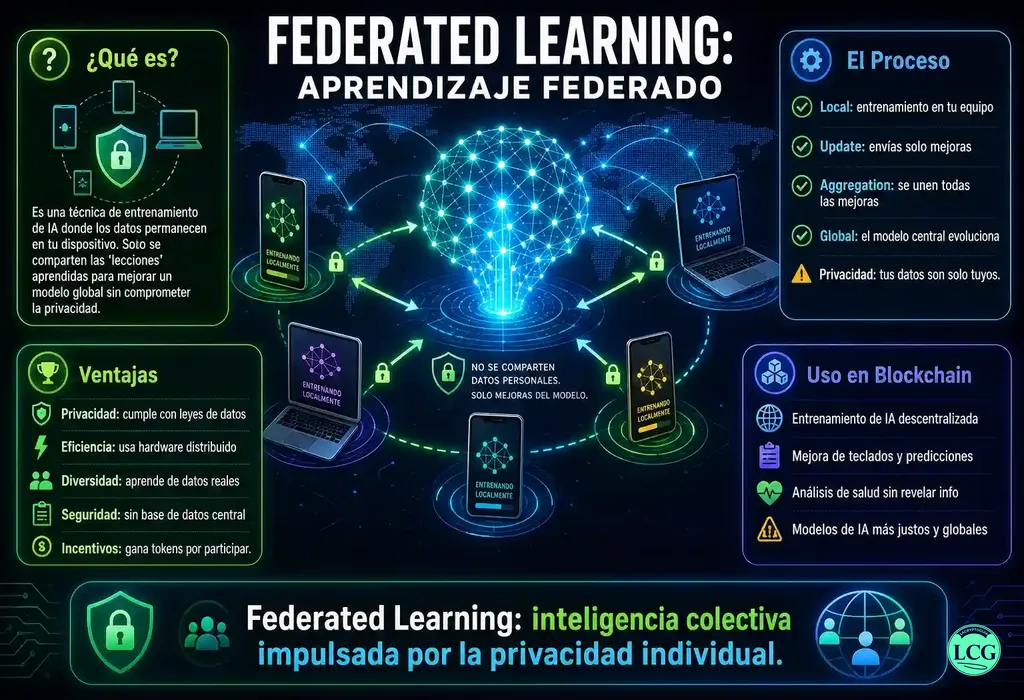
Federated Learning (Aprendizaje Federado) es un paradigma de machine learning descentralizado que permite entrenar un modelo de inteligencia artificial de forma colaborativa sin centralizar los datos de entrenamiento. En lugar de enviar datos sensibles a un servidor central, el modelo viaja a los dispositivos o nodos locales, se entrena con sus datos, y solo las actualizaciones del modelo (gradientes o parámetros) se envían de vuelta para ser agregadas. Esto preserva la privacidad de los datos en origen y es clave para aplicaciones en sectores como salud, finanzas e IoT.
Términos relacionados: Machine Learning • Neural Network • zkML • On-chain Machine Learning • Decentralized AI Compute
❓ ¿Qué es Federated Learning y por qué es crucial para la IA con privacidad?
Federated Learning (FL) es un enfoque revolucionario de machine learning que aborda uno de los mayores dilemas de la IA moderna: la necesidad de grandes cantidades de datos versus el derecho a la privacidad. En lugar de centralizar datos en un servidor, el modelo se envía a los dispositivos o nodos donde residen los datos, se entrena localmente, y solo las actualizaciones del modelo (no los datos) se comparten para mejorar un modelo global.
Este cambio de paradigma, de «llevar los datos al modelo» a «llevar el modelo a los datos», permite que entidades como hospitales, bancos o fabricantes de dispositivos IoT colaboren en el entrenamiento de modelos de IA sin violar regulaciones de privacidad (GDPR, HIPAA) ni comprometer secretos comerciales. La blockchain potencia este modelo al proporcionar un registro inmutable y transparente del proceso, permitiendo incentivos tokenizados para los participantes y creando un mercado de datos privados sin intercambiar los datos en sí.
📖 Definición Técnica
Federated Learning es un proceso iterativo donde un modelo global (por ejemplo, una red neuronal) se distribuye a múltiples clientes. Cada cliente entrena el modelo con sus datos locales, produciendo actualizaciones (gradientes o pesos). Estas actualizaciones se envían a un servidor coordinador (o a un contrato inteligente en el caso descentralizado) que las agrega, típicamente usando Federated Averaging (FedAvg), para actualizar el modelo global. El proceso se repite durante múltiples rondas hasta que el modelo converge. Técnicas avanzadas como Differential Privacy o Computación Homomórfica pueden añadirse para proteger aún más la privacidad de las actualizaciones.
🏛️ Comparativa: FL vs. Aprendizaje Centralizado vs. Aprendizaje Distribuido
Para entender el valor único de Federated Learning, es útil compararlo con otros paradigmas de entrenamiento de IA.
| Aspecto | Federated Learning | Aprendizaje Centralizado | Aprendizaje Distribuido |
|---|---|---|---|
| Ubicación de los datos | Los datos permanecen en los dispositivos/nodos locales | Los datos se recopilan y almacenan en un servidor central | Los datos se distribuyen en múltiples servidores (ej. clúster) |
| Privacidad de datos | Alta (los datos no salen del dispositivo) | Baja (los datos se centralizan, riesgo de filtraciones) | Media (los datos se distribuyen, pero no se protegen inherentemente) |
| Control del usuario | Alto (el usuario mantiene el control de sus datos) | Bajo (el usuario pierde control sobre sus datos) | Medio (depende de la configuración) |
| Cumplimiento normativo | Facilita el cumplimiento (GDPR, HIPAA) | Difícil de cumplir (requiere consentimiento y protección) | Moderado (depende de la implementación) |
| Escalabilidad | Alta (puede usar millones de dispositivos) | Limitada por el ancho de banda y almacenamiento central | Alta (escalable horizontalmente en clústeres) |
| Heterogeneidad de datos | Gestiona datos no-IID (no independientes e idénticamente distribuidos) | Asume datos IID (puede fallar con datos no homogéneos) | Requiere datos balanceados y homogéneos |
| Caso de uso típico | Teclado predictivo en móviles, diagnóstico médico colaborativo | Entrenamiento de modelos en grandes centros de datos | Entrenamiento de modelos grandes en GPUs en clústeres |
💰 Componentes clave y flujo de trabajo del FL
El proceso de Federated Learning se basa en varios componentes y pasos que garantizan la privacidad y la colaboración efectiva.
| Componente / Paso | Descripción | Rol en la Privacidad | Reto Técnico |
|---|---|---|---|
| Servidor Coordinador / Agregador | Inicia el proceso, distribuye el modelo global, recibe y agrega las actualizaciones de los clientes. | Nunca ve los datos crudos, solo recibe actualizaciones del modelo (que pueden estar encriptadas). | Punto centralizado de fallo potencial. En versiones descentralizadas, se reemplaza por un contrato inteligente. |
| Clientes / Nodos Participantes | Los dispositivos o servidores que poseen datos locales (ej: teléfonos, hospitales, empresas). | Mantienen el control total de sus datos. Solo comparten el resultado del aprendizaje, no la materia prima. | Hardware heterogéneo (dispositivos móviles con recursos limitados), conectividad intermitente. |
| Ciclo de Entrenamiento Federado | 1. Selección: Elegir clientes para la ronda. 2. Distribución: Enviar modelo global. 3. Entrenamiento Local: Cada cliente entrena. 4. Agregación: Combinar actualizaciones (ej: con Federated Averaging). | El ciclo garantiza que el aprendizaje sea colaborativo sin intercambio de datos. | Sincronizar a muchos clientes, manejar actualizaciones de modelos de tamaños muy grandes. |
| Protecciones de Privacidad Avanzadas | Técnicas como Diferenciación Privada (Differential Privacy) y Cómputo Seguro Multi-Parte (MPC) o Homomórfico. | Añaden «ruido» matemático a las actualizaciones o las encriptan, haciendo imposible revertirlas a datos originales. | Añaden complejidad computacional y pueden reducir la precisión final del modelo. |
| Mecanismo de Incentivos (Blockchain) | Tokenización de las contribuciones. Los clientes son recompensados con tokens por la calidad y cantidad de su participación. | La blockchain registra la contribución de manera transparente y ejecuta pagos automáticos, fomentando la honestidad. | Medir la «calidad» de una contribución de manera justa y resistente a trampas (PoL, Proof of Learning). |
📈 Principales aplicaciones de Federated Learning
- Salud y Medicina: Entrenar modelos de diagnóstico en imágenes médicas (radiografías, TACs) de múltiples hospitales sin compartir datos de pacientes. Cumplimiento normativo (GDPR, HIPAA). Modelos más robustos y generalizables.
- Finanzas y Detección de Fraude: Bancos colaboran para entrenar un modelo de detección de fraude sin compartir datos sensibles de transacciones de clientes. Protección de secretos comerciales y datos personales.
- Internet de las Cosas (IoT): Dispositivos inteligentes (cámaras de seguridad, sensores industriales) mejoran un modelo de mantenimiento predictivo localmente. Ahorro de ancho de banda y protección de datos sensibles.
- Automóviles Autónomos: Coches de diferentes fabricantes aprenden colectivamente a reconocer situaciones raras de tráfico sin compartir datos de conducción. Acelera el aprendizaje y mejora la seguridad.
- Teclados Predictivos y Asistentes Virtuales: Google Gboard usa FL para mejorar el modelo de predicción de texto sin enviar tus pulsaciones a sus servidores. Apple también lo usa para Siri.
🆚 FL vs. Aprendizaje Centralizado vs. Aprendizaje Distribuido: ¿Cuándo usar cada uno?
La elección del paradigma de aprendizaje depende de los requisitos de privacidad, escalabilidad y control de datos.
| Paradigma | Cuándo usarlo | Ejemplo |
|---|---|---|
| Federated Learning | Cuando los datos son sensibles, están distribuidos en múltiples entidades, o hay restricciones legales para centralizarlos. | Hospitales colaborando en un modelo de diagnóstico sin compartir datos de pacientes. |
| Aprendizaje Centralizado | Cuando los datos ya están centralizados, no hay restricciones de privacidad, y se busca la máxima simplicidad técnica. | Entrenar un modelo de recomendación en un gran dataset de películas (Netflix). |
| Aprendizaje Distribuido | Cuando se necesita escalar el entrenamiento de un modelo grande en un clúster de servidores, sin preocupaciones de privacidad. | Entrenar un modelo de lenguaje grande (LLM) en un clúster de GPUs. |
✅ Ventajas de Federated Learning
- Privacidad por Diseño: Es la mayor ventaja. Permite usar datos que de otro modo serían inaccesibles por razones legales o éticas.
- Eficiencia en el Edge: Reduce la necesidad de enviar grandes volúmenes de datos a la nube, ahorrando ancho de banda y costos de almacenamiento.
- Personalización: El modelo global puede adaptarse localmente en cada dispositivo, ofreciendo una experiencia personalizada sin comprometer la privacidad.
- Colaboración Sin Fricciones: Permite que entidades que son competidoras (ej. bancos) colaboren en áreas de beneficio mutuo sin riesgos de fuga de información.
- Cumplimiento Normativo: Facilita el cumplimiento de regulaciones como GDPR, CCPA e HIPAA, que exigen la protección de datos personales.
⚠️ Críticas y desafíos
- Complejidad Técnica y Costo: Coordinar, agregar y asegurar el entrenamiento distribuido es mucho más complejo que el centralizado, requiriendo infraestructura especializada.
- Comunicaciones Costosas: Enviar actualizaciones de modelos grandes (miles de millones de parámetros) puede ser pesado, aunque hay técnicas de compresión y poda.
- Heterogeneidad de Datos (Non-IID): Los datos en cada dispositivo no son una muestra aleatoria del total (ej: tus fotos son diferentes a las mías). Esto puede ralentizar o perjudicar la convergencia del modelo.
- Ataques y Robustez: Los clientes maliciosos pueden enviar actualizaciones corruptas para dañar el modelo global (ataques de envenenamiento). Se necesitan mecanismos robustos de detección y defensa.
- Medición de la Calidad de la Contribución: En sistemas con incentivos tokenizados, medir la «calidad» de una contribución de manera justa y resistente a trampas es un desafío abierto.
🧠 Guía práctica: Cómo afecta Federated Learning a tu operativa
- Si eres desarrollador de aplicaciones: Considera usar FL para entrenar modelos de recomendación, predicción o clasificación sin violar la privacidad de tus usuarios. Frameworks como TensorFlow Federated o PySyft facilitan la implementación.
- Si eres un profesional de salud o finanzas: Evalúa cómo FL puede permitir la colaboración entre instituciones sin compartir datos sensibles. Proyectos como Numerai en finanzas son un ejemplo exitoso.
- Si eres inversor en cripto: Investiga proyectos que combinen FL con blockchain (ej: Ocean Protocol, Bittensor, Numerai). Estos proyectos tokenizan la contribución de datos y el entrenamiento de modelos, creando mercados descentralizados de IA.
- Si eres usuario preocupado por la privacidad: Busca aplicaciones que usen FL (ej: Gboard, Siri) y apoya proyectos que prioricen la privacidad de los datos sobre la recolección masiva.
- Si eres investigador: El campo del FL está lleno de desafíos abiertos: cómo manejar datos no-IID, cómo diseñar mecanismos de incentivos justos, cómo proteger contra ataques de envenenamiento, etc.
🔮 El futuro de Federated Learning
Federated Learning se perfila como una tecnología fundamental para la próxima generación de IA. Las perspectivas para los próximos años incluyen:
- Adopción masiva en sectores regulados: Salud, finanzas y gobierno adoptarán FL para cumplir con normativas de privacidad mientras aprovechan el poder de la IA colaborativa.
- Integración con Web3 y DePIN: Redes de infraestructura física descentralizada (DePIN) usarán FL para entrenar modelos de IA en dispositivos IoT, recompensando a los participantes con tokens.
- Mercados de Datos Privados: Plataformas como Ocean Protocol permitirán a los usuarios vender el acceso a su «aprendizaje» (no a sus datos) a través de FL, creando una nueva economía de datos.
- Mejoras en eficiencia y seguridad: Técnicas como la poda de modelos, la compresión de gradientes y la computación homomórfica harán que FL sea más rápido, barato y seguro.
- Estandarización: Se espera que surjan estándares industriales para la interoperabilidad entre diferentes sistemas de FL, facilitando la colaboración entre entidades.
🎯 Conclusión: El puente entre los datos privados y la IA poderosa
Federated Learning es mucho más que una técnica de machine learning; es una filosofía de diseño para una IA ética y sostenible. Al mantener los datos donde se generan, empodera a los individuos y organizaciones, mitigando los riesgos de vigilancia masiva y violaciones de datos que plagan el modelo centralizado actual.
Su unión con la blockchain y la criptoeconomía (tokenomics) es natural y poderosa, creando el marco para una nueva economía de datos colaborativa. En el futuro, podríamos ser dueños de nuestros «datos gemelos» (representaciones encriptadas de nuestros hábitos, salud, preferencias) y licenciar selectivamente su uso para entrenar modelos específicos, recibiendo micropagos en tokens por ello, todo ello de forma automática y segura gracias a los smart contracts. El Aprendizaje Federado es la tecnología que puede hacer realidad la promesa de la Web3: una Internet donde los usuarios sean soberanos de su información y participen equitativamente en el valor que genera.
❓ Preguntas Frecuentes sobre Federated Learning
📚 ¿Quieres profundizar en IA descentralizada y privacidad?
Explora más recursos de La Cryptoguía sobre inteligencia artificial y protección de datos:
🔐 Privacidad de Datos – Conceptos clave para proteger tu información.
🌉 ¿Qué es la Tokenomics? – Para diseñar incentivos en redes descentralizadas.
🔷 ¿Qué es Blockchain? – La base para la coordinación descentralizada.
💡 Cómo Auditar un Token – Un paso necesario antes de participar en cualquier red de FL con incentivos tokenizados.
🚀 ¿Empezando en Crypto?
Si eres nuevo, empieza con nuestra guía completa para principiantes para entender los fundamentos antes de adentrarte en la IA descentralizada.
📋 ¿Por qué confiar en esta definición? Cada término de la Cryptopedia sigue una metodología de verificación con fuentes primarias, whitepapers y legislación oficial. Conoce nuestro proceso →
⚠️ Disclaimer: Este artículo es informativo y educativo. No constituye asesoramiento financiero, legal, médico o técnico. Federated Learning es una tecnología compleja y en evolución. Su implementación en entornos productivos y regulados requiere una cuidadosa consideración de aspectos técnicos, legales y de seguridad. Siempre consulta con profesionales especializados.
📅 Actualizado: Marzo 2026
📖 Categoría: Web3, NFTs y DAOs / AI en Web3